
Normalization or standardization is the process of re-scaling original data without changing its original nature. It is the technique often applied as part of data pre-processing in Machine Learning. The main aim of normalization is to change the value of data in the dataset to a common scale, without distorting the differences in the ranges of value.We often define new boundary (most common is (0,1),(-1,1)) and convert data accordingly. This technique is useful in classification algorithms involving neural networks or distance-based algorithm (e.g. KNN, K-means).
In Z score normalization, the values are normalized based on the mean and standard deviation of attribute A. For Vi value of attribute A, normalized value Ui is given as,
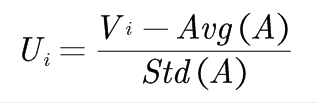
where Avg(A) and Std(A) represents the average and standard deviation respectively for the values of attribute A.
Let’s see an example: Consider that the mean and standard deviation of values for attribute income $54,000 and $16,000 respectively. With z-score normalization, a value of $73,000 for income is normalized to (73,000-54,000)/16,000=1.225.
In Python:
from sklearn.preprocessing import StandardScaler
X=[[101,105,222,333,225,334,556],[105,105,258,354,221,334,556]]
print("Before standardisation X values are ", X)
sc_X = StandardScaler()
X = sc_X.fit_transform(X)
print("After standardisation X values are ", X)Output:
Before standardization X values are
[[101, 105, 222, 333, 225, 334, 556],
[105, 105, 258, 354, 221, 334, 556]]
After standardization X values are
[-1. 0. -1. -1. 1. 0. 0.]
[ 1. 0. 1. 1. -1. 0. 0.]]
To read more on normalization visit here.
No Comments